Parallel Stream Processing in Java 8 - Performance Comparison of Sequential vs Parallel Stream Processing
Parallel processing is everywhere in today's world. Due to the increasing number of CPU cores and decreasing hardware costs making cluster systems cheaper, parallel processing seems to be the next big thing.
Java 8 addresses this fact with the new Stream API and simplified creation of parallel processing on collections and arrays. Let's see how this works.
Suppose myList is a list of integers containing 500,000 integer values. In the pre-Java 8 era, the way to sum these integer values was using a for-each loop.
for (int i :myList)
result+=i;
Starting from Java 8, we can do the same with streams:
myList.stream().sum();
Parallelizing the processing is very easy - we just replace stream with the keyword parallelStream(), or if we already have a stream, use parallel().
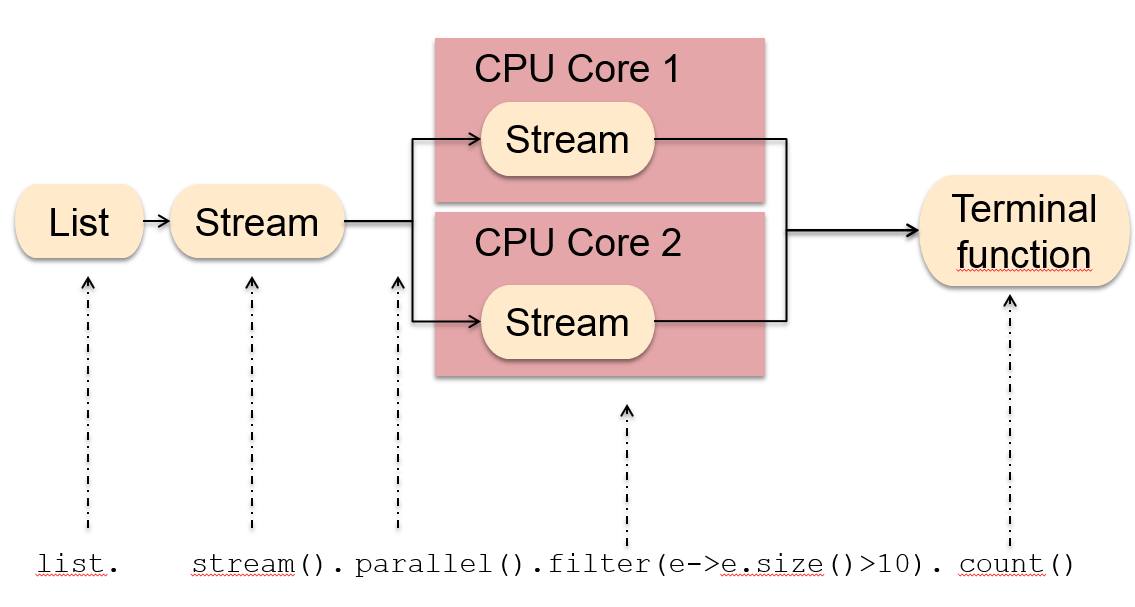
So the parallelized stream operation code should look like this:
myList.parallelStream().sum()
This simple change easily distributes the computation across threads and available CPU cores. But we know that the overhead of multithreading and parallel processing is expensive. The question is when using parallel streams is more beneficial for performance than serial streams.
First, let's look at what happens behind the scenes. Parallel streams use the Fork/Join framework for processing. This means the stream-source is forked (i.e., split) and handed to workers in the fork/join-pool for execution.
But here we find the first point to consider - not all stream-sources can be split as easily as others. Think about ArrayList, whose internal data representation is based on an array. Splitting such a stream is easy because you can calculate the index of the middle element and split the array.
If we have a LinkedList, splitting the data elements becomes more complicated. The implementer must start from the first element and browse through all elements to find elements where splitting can occur. Therefore, LinkedLists perform poorly with parallel streams.
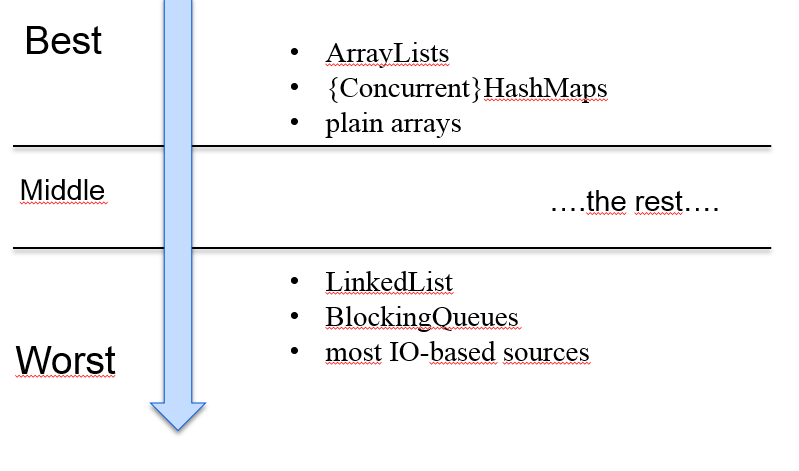
This is the first fact we can retain about parallel stream performance:
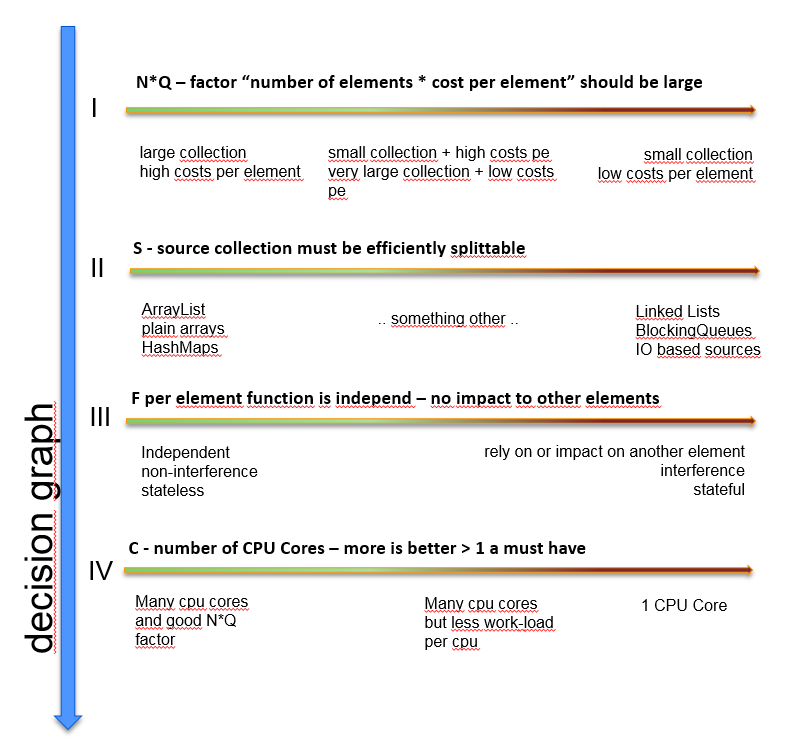
S - Source collection must be efficiently splittable
Splitting a collection, managing fork and join tasks, object creation, and garbage collection is also algorithmic overhead. This is only worthwhile when the work to be done on CPU cores is non-trivial and/or the collection is large enough. Of course, we also need many CPU cores.
A bad example is calculating the maximum of 5 integer values:
IntStream.rangeClosed(1, 5).reduce( Math::max).getAsInt();
Here the overhead of preparing and processing data for fork/join is so large that serial streams are much faster. The Math.max function isn't very CPU-intensive here, and we have few data elements.
However, when the function executed on each element is more complex - specifically, "more CPU-intensive" - it becomes increasingly worthwhile. For example, calculating the sine of each element instead of the maximum.
When programming a chess game, evaluating each move is also such an example. Many evaluations can be done in parallel. And we have a large number of possible next moves.
This is perfect for parallel processing.
And this is the second fact we can retain about parallel stream performance:
NQ - The coefficient of "number of elements × cost per element" should be large
But this also means conversely, when the operation cost per element is high, the collection can be smaller.
Or when the operation per element isn't that intensive, we need a large collection with many elements for parallel stream usage to pay off.
This directly depends on the third fact we can retain:
C - Number of CPU cores - more is better, > 1 is a must
On a single-core machine, parallel streams always perform worse than serial streams due to management overhead. It's like a company having many project managers but only one person doing the work.
More is better - unfortunately, in the real world, this isn't true in all cases, for example, when the collection is too small and CPU cores start up - perhaps from energy-safe mode - only to find there's nothing to do.
There are also requirements for the function on each element to determine whether to use parallel streams. This is less about performance and more about whether parallel streams work as expected.
The function must be...
- ...independent, meaning the computation of each element cannot depend on or affect the computation of any other element.
- ...non-interfering, meaning the function doesn't modify the underlying data source during processing.
- ...stateless.
Here's an example of a stateful lambda function used in a parallel stream. This example is taken from the Java JDK API and shows a simplified distinct() implementation:
Set seen = Collections.synchronizedSet(new HashSet());
stream.parallel().map(e -> { if (seen.add(e)) return 0; else return e; })...
So this brings us to the fourth fact we can retain:
F - The function per element must be independent
Summary:
Are there other situations where we shouldn't parallelize our streams? Yes, there are.
Always consider what your per-element function is doing and whether it's suitable for the world of parallel processing. When your function is calling some synchronized functionality, you may not get any benefit from parallelizing your stream because your parallel stream will often wait at this synchronization barrier.
The same problem occurs when you call blocking I/O operations.
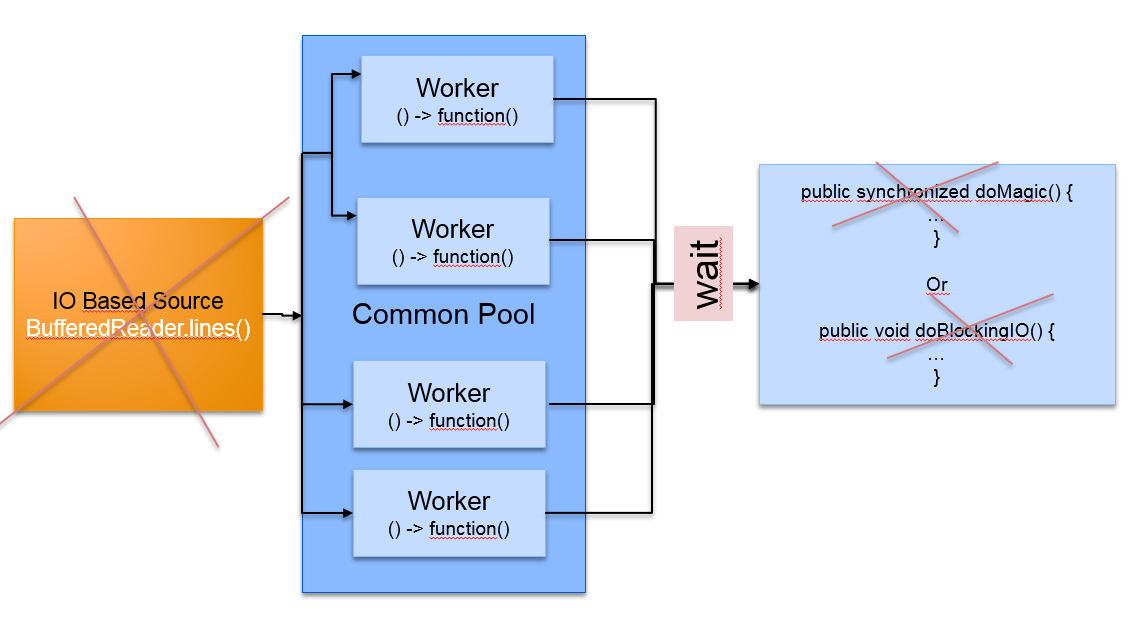
On this point, using I/O-based sources as streams is also well-known because data is read sequentially, making such sources difficult to split.