[Repost] Interview Questions About Redis 6.0 and Later
1. Why Did Redis Initially Choose a Single-Threaded Model (Benefits of Single-Threading)?
Redis developed a network event handler based on the Reactor pattern, called the file event handler. It consists of 4 parts: multiple sockets, I/O multiplexing program, file event dispatcher, and event handlers. Because the file event dispatcher queue is consumed by a single thread, Redis is called a single-threaded model.
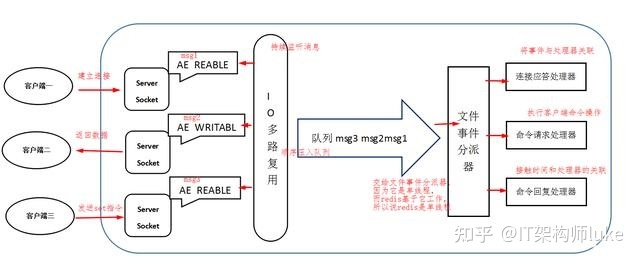
Generally speaking, Redis's bottleneck is not the CPU, but memory and network. If you want to use multiple CPU cores, you can set up multiple Redis instances.
Redis 4.0 already had the concept of multi-threading, such as Redis deleting objects in the background through multi-threading and blocking commands implemented through Redis modules.
1.1 Why Was Redis Designed as Single-Threaded?
1.1.1 I/O Multiplexing
Redis Top-Level Design:
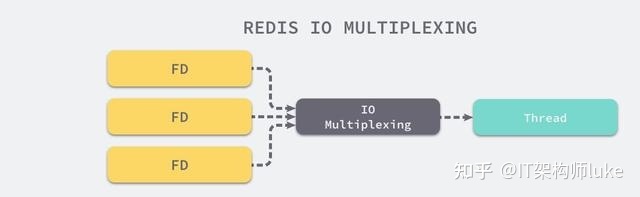
FD is a file descriptor, indicating whether the current file is in a readable, writable, or error state. Using I/O multiplexing to simultaneously monitor the readable and writable states of multiple file descriptors. You can understand this as having multi-threaded characteristics.
Once a network request is received, it's quickly processed in memory. Since the vast majority of operations are pure memory operations, processing speed is very fast. In single-threaded mode, even with many network connections, because of I/O multiplexing, they can be handled quickly in high-speed memory processing.
1.1.2 High Maintainability
Although multi-threaded models perform well in some aspects, they introduce uncertainty in program execution order and bring a series of concurrent read/write problems. Single-threaded mode makes debugging and testing more convenient.
1.1.3 Memory-Based, Still Efficient in Single-Threaded State
Multi-threading can fully utilize CPU resources, but for Redis, being memory-based means it's extremely fast - capable of handling 100,000 user requests per second. If 100,000 per second isn't enough, we can use Redis sharding to distribute across different Redis servers. This approach avoids introducing a lot of multi-threaded operations in a single Redis service.
Being memory-based, unless doing AOF backup, there's basically no I/O operations involved. Since data read/write only happens in memory, processing speed is very fast; using a multi-threaded model to handle all external requests may not be a good solution.
Now we know it can basically be summarized in two sentences: memory-based with multiplexing technology, single-threaded is fast while maintaining multi-threaded characteristics. Because there's no need for multi-threading.
2. Why Did Redis Add Multi-Threading After 6.0 (In Some Cases, Single-Threading Has Drawbacks That Multi-Threading Can Solve)?
Because Redis's bottleneck is not the CPU, but memory and network.
If memory is insufficient, you can add memory or optimize data structures, but network performance optimization is the main concern - network I/O read/write occupies most of the CPU time during Redis execution. If network processing is made multi-threaded, it will significantly improve overall Redis performance.
Redis's multi-threading is only used for network data read/write and protocol parsing, command execution is still single-threaded. This design avoids making Redis complex due to multi-threading, needing to control concurrency issues for keys, lua, transactions, LPUSH/LPOP, etc.
3. Redis Added Some Delete Operations in Recent Versions That Can Be Processed Asynchronously by Other Threads, Such as: UNLINK, FLUSHALL ASYNC, and FLUSHDB ASYNC. Why Do We Need These Delete Operations, and Why Do They Need Asynchronous Multi-Threaded Processing?
We know Redis can use the del command to delete an element. If this element is very large, occupying tens or hundreds of megabytes, it can't be completed quickly, requiring multi-threaded asynchronous support.
Now deletion can be done in the background.
Optimization directions:
- Improve network I/O performance, typical implementations like using DPDK to replace the kernel network stack.
- Use multi-threading to fully utilize multiple cores, typical implementations like Memcached.
So in summary, Redis supports multi-threading mainly for two reasons:
- Can fully utilize server CPU resources - currently the main thread can only use one core.
- Multi-threaded tasks can share Redis synchronous I/O read/write load.
4. Is Multi-Threading Enabled by Default in Redis 6.0?
No, configure it in the conf file:
io-threads-do-reads yes
io-threads thread_count
Official recommendation: For 4-core machines, set 2 or 3 threads; for 8-core, set 6 threads. Thread count must be less than machine cores, preferably not exceeding 8.
5. Redis 6.0 Multi-Threading Implementation Mechanism?
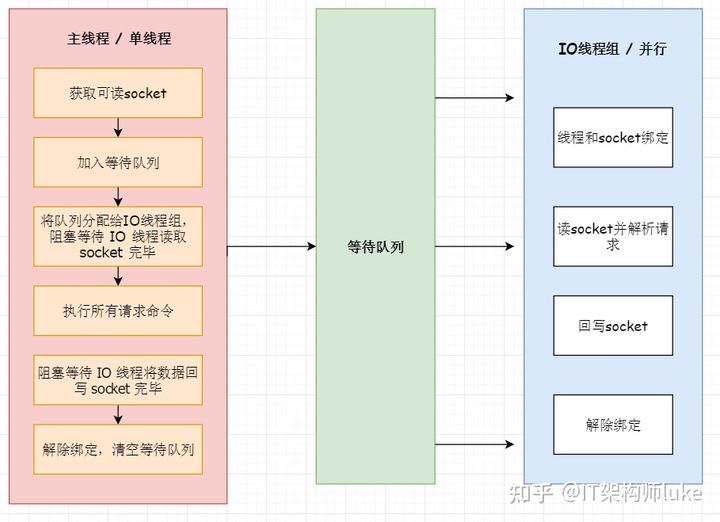
Brief process description:
- Main thread handles connection requests, gets Socket and puts it in global read queue.
- After main thread processes read events, distributes connections to I/O threads via RR (Round Robin).
- Main thread blocks waiting for I/O threads to finish reading Socket.
- Main thread executes request commands in single-threaded manner - request data is read and parsed but not executed.
- Main thread blocks waiting for I/O threads to write data back to Socket.
- Unbind, clear waiting queue.
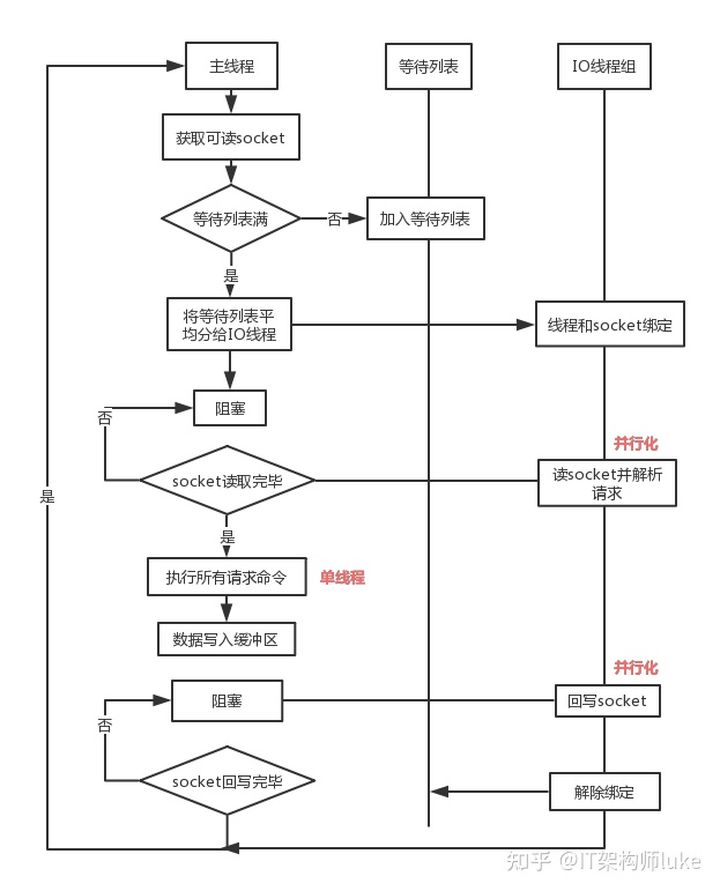
This design has the following characteristics:
- I/O threads either read Socket simultaneously or write simultaneously, never both at once.
- I/O threads only handle Socket read/write and command parsing, not command processing.
6. After Enabling Multi-Threading, Will There Be Thread Concurrency Safety Issues?
No, Redis's multi-threading is only for network data read/write and protocol parsing, command execution is still single-threaded sequential execution.
7. I/O Multiplexing Is Often Mentioned in Redis Threading - How to Understand It?
This is an I/O model, the classic Reactor design pattern, sometimes called asynchronous blocking I/O.
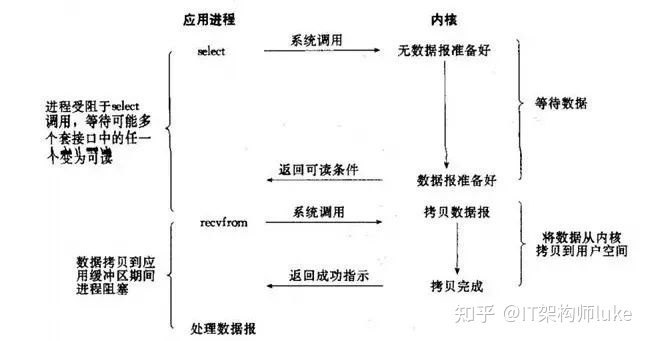
Multiplexing refers to multiple Socket connections, reusing refers to reusing one thread. Main multiplexing technologies: Select, Poll, Epoll.
Epoll is the newest and currently best multiplexing technology. Using multiplexing technology allows a single thread to efficiently handle many connection requests (minimizing network I/O time consumption), and Redis operates on data in memory very fast (in-memory operations won't be a performance bottleneck here), mainly these two points make Redis have very high throughput.
Redis chose single-threaded model mainly because CPU is not Redis server's bottleneck, so the performance improvement from multi-threading doesn't offset its development and maintenance costs, the system's performance bottleneck is mainly in network I/O operations; and Redis introduced multi-threading for performance considerations - for some large key-value pair delete operations, releasing memory space non-blockingly through multi-threading can also reduce blocking time on Redis main thread, improving execution efficiency.
In one sentence: Previously used single-threading because memory-based is fast, and multiplexing serves its purpose - it was sufficient. Now introducing multi-threading because certain operations need optimization, like delete operations.
Source: How to Answer Interview Questions After Redis 6.0 Multi-Threading Release?